Em aplicações Java tradicionais, acessar um banco de dados utilizando JDBC significa escrever SQL, abrir conexões, percorrer ResultSets e converter manualmente registros em objetos Java. Essa abordagem funciona muito bem para compreender os fundamentos da persistência, mas rapidamente se torna repetitiva conforme o projeto cresce.
Neste artigo vamos entender por que surgiu o conceito de Object-Relational Mapping (ORM), qual o papel da Jakarta Persistence API (JPA) dentro do ecossistema Java e qual o papel do _Hibernate_ nesse contexto.
#🧠 Rápida Revisão de JDBC
Antes de avançarmos para ORM, vamos recordar rapidamente como realizávamos persistência utilizando JDBC (Java Database Connectivity).
Exemplo de consulta:
String sql =
"SELECT * FROM seller WHERE id = ?";
PreparedStatement stmt =
conn.prepareStatement(sql);
stmt.setInt(1, id);
ResultSet rs = stmt.executeQuery();Após executar a consulta precisávamos converter manualmente os resultados:
Seller seller = new Seller();
seller.setId(
rs.getInt("id")
);
seller.setName(
rs.getString("name")
);
seller.setEmail(
rs.getString("email")
);#Problemas da Abordagem JDBC
Embora funcional, essa abordagem possui algumas limitações:
Muito código repetitivo
Sempre precisamos:
- Abrir conexão;
- Criar comandos SQL;
- Executar consultas;
- Percorrer ResultSets;
- Criar objetos manualmente.
Forte acoplamento ao SQL
Uma simples mudança na estrutura da tabela pode exigir modificações em diversos pontos do sistema.
Conversão Manual
O programador precisa constantemente converter:
Banco
↓
ResultSet
↓
Objeto Javae vice-versa.
Conclusão: embora seja importante conhecer JDBC, essa abordagem não é a mais produtiva para aplicações corporativas modernas.
#🤔 O Problema do Mapeamento Objeto-Relacional
A maior parte das aplicações backend modernas é desenvolvida utilizando Orientação a Objetos.
Exemplo:
public class Seller {
private Integer id;
private String name;
private Department department;
}Entretanto, bancos relacionais trabalham com tabelas:
CREATE TABLE seller (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
department_id INTEGER
);Observe que os dois modelos representam o mesmo domínio de formas bem diferentes.
#Object-Relational Impedance Mismatch
Essa divergência e a dificuldade de mapear objetos Java para registros em bancos de dados relacionais recebe o nome de Object-Relational Impedance Mismatch ou Descasamento de Impedância Objeto-Relacional
As diferentes formas de representar o mesmo domínio gera problemas de conversão entre os dois modelos. Sem uma ferramenta de mapeamento, o programador precisa escrever muito código repetitivo para realizar essa conversão (como vimos usando JDBC puro).
Diferenças Entre os Modelos
| Orientação a Objetos | Banco Relacional |
|---|---|
| Classe | Tabela |
| Objeto | Registro |
| Atributo | Coluna |
| Associação | Chave Estrangeira |
| Herança | Não possui equivalente direto |
| Coleções | Tabelas relacionadas |
Exemplo
Orientação a Objetos:
seller.getDepartment()
.getName();Banco Relacional:
SELECT d.name
FROM seller s
INNER JOIN department d
ON d.id = s.department_idMesma informação, mas com representações diferentes.
#🔄 O Que é ORM?
📌 ORM significa: Object Relational Mapping ou Mapeamento Objeto-Relacional.
É uma técnica que permite mapear automaticamente conceitos de orientação a objetos para o modelo relacional.
| Orientação a Objetos | Modelo Relacional |
|---|---|
| Classe | Tabela |
| Objeto | Linha |
| Atributo | Coluna |
| Associação | Chave Estrangeira (FK) |
Além disso, o ORM permite que o desenvolvedor trabalhe com objetos, sem precisar escrever SQL manualmente, enquanto os mantém em um contexto de persistência, gerenciado pela ferramenta de ORM.
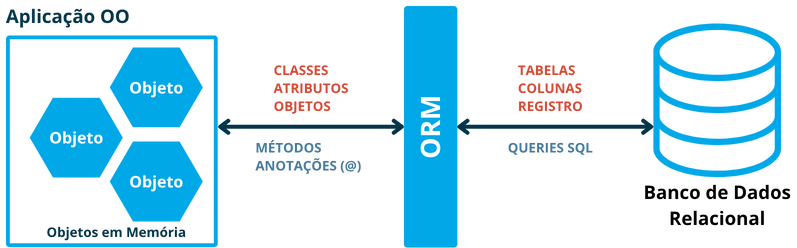
A ténica de ORM faz o “meio de campo” entre os dois modelos, permitindo que o desenvolvedor trabalhe com objetos Java, enquanto a ferramenta de ORM cuida da conversão para SQL e da persistência no banco de dados.
O desenvolvedor deve ser capaz de trabalhar com objetos Java, sem precisar se preocupar com a conversão para SQL. Em um relacionamento entre as entidades Seller e Department, por exemplo, o desenvolvedor deve ser capaz de escrever:
seller.getDepartment();em vez de:
SELECT *
FROM seller
INNER JOIN department ...Alguns benefícios do uso de ORM incluem:
- Menos código repetitivo;
- Maior produtividade;
- Menor acoplamento;
- Melhor integração com OO;
- Portabilidade entre bancos.
#Outros problemas que o ORM resolve
- Contexto de persistência: O ORM mantém os objetos em um contexto de persistência, permitindo que o desenvolvedor trabalhe com eles sem se preocupar com a sincronização com o banco de dados.
- Cache de objetos: O ORM pode armazenar objetos em memória, reduzindo a necessidade de acessar o banco de dados repetidamente.
- Gerenciamento de transações: O ORM facilita o gerenciamento de transações, garantindo a integridade dos dados.
- Lazy Loading: O ORM pode carregar objetos somente quando necessário, melhorando o desempenho da aplicação.
#Limitações
ORM não elimina a necessidade de conhecer:
- SQL;
- Modelagem Relacional;
- Índices;
- Performance.
ORM é uma ferramenta poderosa, mas não substitui o conhecimento de banco de dados. O desenvolvedor ainda precisa entender como os dados são armazenados e recuperados, e como otimizar consultas para garantir a performance da aplicação.
#⚙️ JPA e Hibernate
Cada linguagem de programação possui suas próprias ferramentas de ORM. Em Python, por exemplo, uma das ferramentas de ORM mais popular é o SQLAlchemy. No ecossistema .NET, a ferramenta de ORM mais popular é o Entity Framework. No PHP, com o framework Laravel, a ferramenta de ORM mais popular é o Eloquent. Desenvolvedores da plataforma Node.js podem utilizar o Sequelize, Prisma, entre outras, como ferramentas de ORM.
No ecossistema Java, temos uma especificação padrão de ORM chamada JPA (Jakarta Persistence API), que define como a persistência de dados deve ser realizada em aplicações Java. Com base nessa especificação, existem diversas implementações de ORM, sendo a mais popular o Hibernate.
#O Que é JPA?
📌 JPA significa: Jakarta Persistence API
A JPA é uma especificação padrão da plataforma Jakarta EE (antiga Java EE) que define como a persistência de dados e ORM devem ser realizados em aplicações Java.
A JPA é apenas uma especificação e pode ser consultada na íntegra em: https://jakarta.ee/specifications/persistence/. Ela define:
- Interfaces;
- Contratos;
- Regras;
- Anotações.
A arquitetura de uma aplicação que utiliza JPA é composta por três camadas:
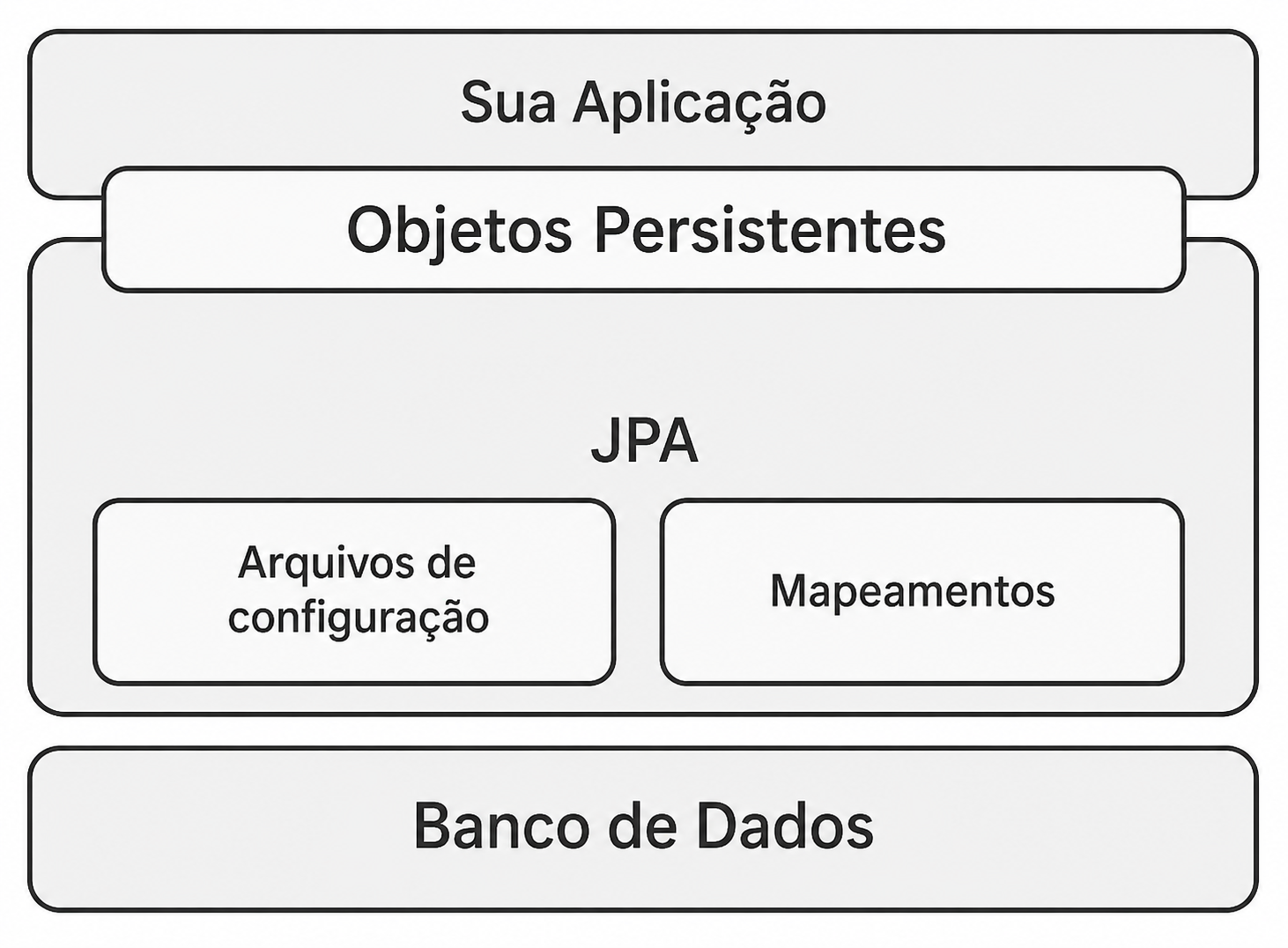
- Aplicação Java: onde o desenvolvedor escreve o código da aplicação, com suas classes de domínio, regras de negócio e lógica de apresentação;
- Camada JPA: com suas interfaces, contratos e anotações, que definem como a persistência de dados deve ser realizada, utilizando uma implementação de ORM;
- Banco de Dados: onde os dados são armazenados e recuperados, utilizando SQL.
As classes de domínio da aplicação são mapeadas para tabelas do banco de dados, sendo chamadas de entidades, e os objetos Java do domínio são gerenciados pela camada JPA, chamados então de objetos persistentes.
#O que é Hibernate?
Como aprendemos, a JPA não executa nada sozinha. Para que a persistência funcione, precisamos de uma implementação da especificação.
A implementação mais popular da JPA é o Hibernate, que é um framework de ORM para Java, que implementa a especificação JPA e adiciona funcionalidades adicionais, como cache de segundo nível, suporte a consultas nativas, entre outras.
Você pode consultar a documentação do Hibernate em: https://hibernate.org/orm/. Aqui vamos nos concentrar na compreensão da especificação JPA e desenvolver nossos exemplos com base nela, utilizando o Hibernate como implementação.
JPA x Hibernate
| JPA | Hibernate |
|---|---|
| Especificação | Implementação |
| Define contratos | Executa os contratos |
| Padroniza APIs | Implementa APIs |
Arquitetura de uma aplicação JPA com Hibernate
Uma aplicação JPA com Hibernate utiliza uma arquitetura onde a camada JPA é implementada pelo Hibernate. A camada de acesso a dados da aplicação (usando o padrão DAO ou Repository, por exemplo) permite que ela interaja com a camada de persistência JPA. Por sua vez, a camada de persistência, utiliza a implementação do Hibernate, que interage com o banco de dados, utilizando JDBC para executar as operações de persistência.
O Hibernate também disponibiliza uma API própria, que pode ser utilizada diretamente, sem passar pela camada JPA. No entanto, é recomendável utilizar a API JPA, pois ela é padronizada e permite a portabilidade entre diferentes implementações de ORM.
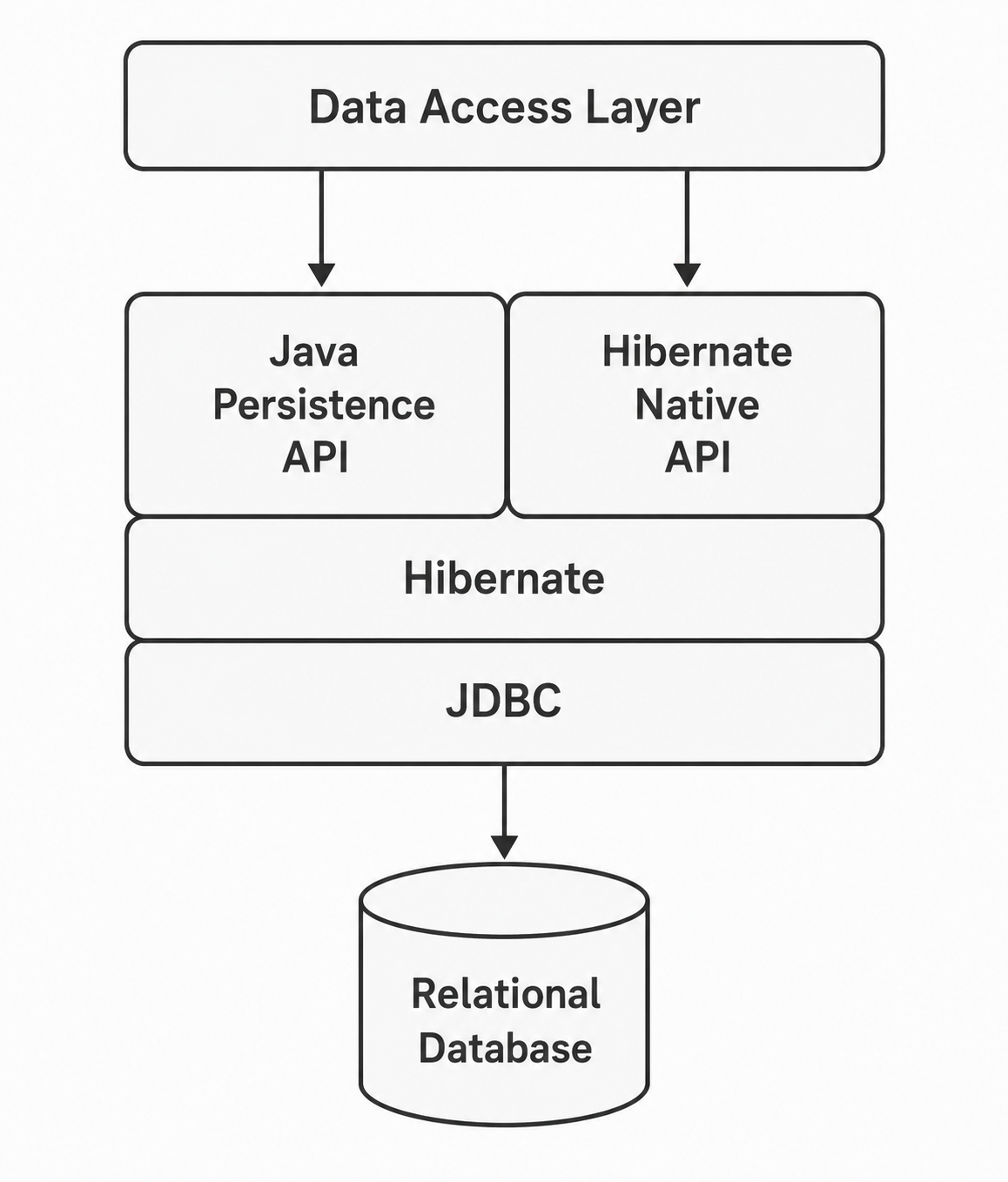
✨ Observe que o Hibernate continua utilizando JDBC internamente.
#Principais Componentes da JPA
Os principais conceitos e componentes da JPA são:
Entity
- Uma entidade é uma classe persistente cujo estado pode ser armazenado e recuperado de um banco de dados através da JPA.
- Podem ser mapeadas para tabelas do banco de dados, e cada instância da entidade corresponde a uma linha da tabela.
- Contém atributos que representam as colunas da tabela, e métodos que representam as operações de persistência.
EntityManager
- Gerencia o ciclo de vida das entidades, permitindo que sejam persistidas, atualizadas, removidas e consultadas no banco de dados.
- De forma superficial, podemos dizer que o
EntityManagercorresponde ao objetoConnectiondo JDBC, mas com funcionalidades adicionais, como o gerenciamento do contexto de persistência. - Geralmente temos uma instância de
EntityManagerpor transação/requisição.
EntityManagerFactory
- Cria instâncias de
EntityManager, que são utilizadas para interagir com o banco de dados. - Geralmente temos uma única instância de
EntityManagerFactorypor aplicação, que é criada no início da aplicação e destruída no final.
Contexto de Persistência
- É um cache de objetos persistentes, que mantém os objetos em memória enquanto a transação está ativa.
- Permite que o desenvolvedor trabalhe com os objetos sem se preocupar com a sincronização com o banco de dados.
- É gerenciado através do
EntityManager, que mantém os objetos em memória enquanto a transação está ativa, e sincroniza com o banco de dados quando a transação é finalizada.
Persistence Unit
- É uma unidade de configuração da JPA, que define como a persistência de dados deve ser realizada em uma aplicação.
- É definida no arquivo
persistence.xml, que contém informações sobre a conexão com o banco de dados, as entidades mapeadas, as propriedades de configuração do Hibernate, entre outras informações.
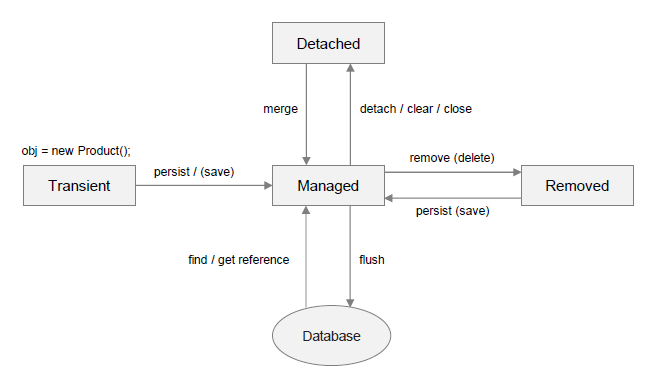
Estados das Entidades
As entidades mapeadas podem estar em quatro estados diferentes:
-
Transient: a entidade foi criada, mas ainda não foi persistida no banco de dados. Ela não possui um identificador (ID) e não está associada a um contexto de persistência.
Seller seller = new Seller(); seller.setName("John Doe"); // seller está no estado Transient -
Managed: a entidade está associada a um contexto de persistência e possui um identificador (ID). Ela pode ser persistida, atualizada ou removida do banco de dados.
EntityManager em = entityManagerFactory.createEntityManager(); em.getTransaction().begin(); // Iniciando a transação // seller está no estado Managed Seller seller = em.find(Seller.class, 1); // Recuperando a entidade do banco de dados com ID 1 seller.setName("Jane Doe"); // Atualizando o nome da entidade em.getTransaction().commit(); // Finalizando a transação- No exemplo acima, a entidade
sellerestá no estado Managed enquanto a transação está ativa. - Quando a transação é finalizada, o estado da entidade é sincronizado com o banco de dados.
- Como executamos uma atualização no nome da entidade, o Hibernate irá gerar um comando SQL
UPDATEpara atualizar o registro correspondente no banco de dados.
- No exemplo acima, a entidade
-
Detached: a entidade foi persistida no banco de dados, mas não está mais associada a um contexto de persistência. Ela possui um identificador (ID), mas não pode ser atualizada ou removida do banco de dados.
EntityManager em = entityManagerFactory.createEntityManager(); em.getTransaction().begin(); // Iniciando a transação Seller seller = em.find(Seller.class, 1); em.getTransaction().commit(); // Finalizando a transação // seller está no estado Detached seller.setName("John Smith"); // Atualizando o nome da entidade- No exemplo acima, a entidade
sellerestá no estado Detached após a transação ser finalizada. - A instrução
seller.setName("John Smith");não irá gerar um comando SQLUPDATE, pois a entidade não está mais associada a um contexto de persistência.
- No exemplo acima, a entidade
-
Removed: a entidade foi marcada para remoção do banco de dados, mas ainda não foi removida. Ela está associada a um contexto de persistência e possui um identificador (ID).
EntityManager em = entityManagerFactory.createEntityManager(); em.getTransaction().begin(); // Iniciando a transação Seller seller = em.find(Seller.class, 1); em.remove(seller); // Marcando a entidade para remoção em.getTransaction().commit(); // Finalizando a transação- No exemplo acima, a entidade
sellerestá no estado Removed após a instruçãoem.remove(seller);. - Quando a transação é finalizada, o Hibernate irá gerar um comando SQL
DELETEpara remover o registro correspondente no banco de dados.
- No exemplo acima, a entidade
#📦 Preparando o Ambiente
Após essa introdução teórica, vamos preparar o ambiente para a primeira prática de ORM com JPA e Hibernate.
Nesta prática utilizaremos:
- Maven
- PostgreSQL
- Hibernate ORM
- Jakarta Persistence API
Contexto e Modelo de Dados
Para as práticas desenvolvidas nesta série de artigos, utilizaremos como exemplo o domínio de uma plataforma de cursos online, inicialmente com as entidades instrutor, curso e aula. Observe o diagrama ER abaixo, que representa o modelo de dados da aplicação:
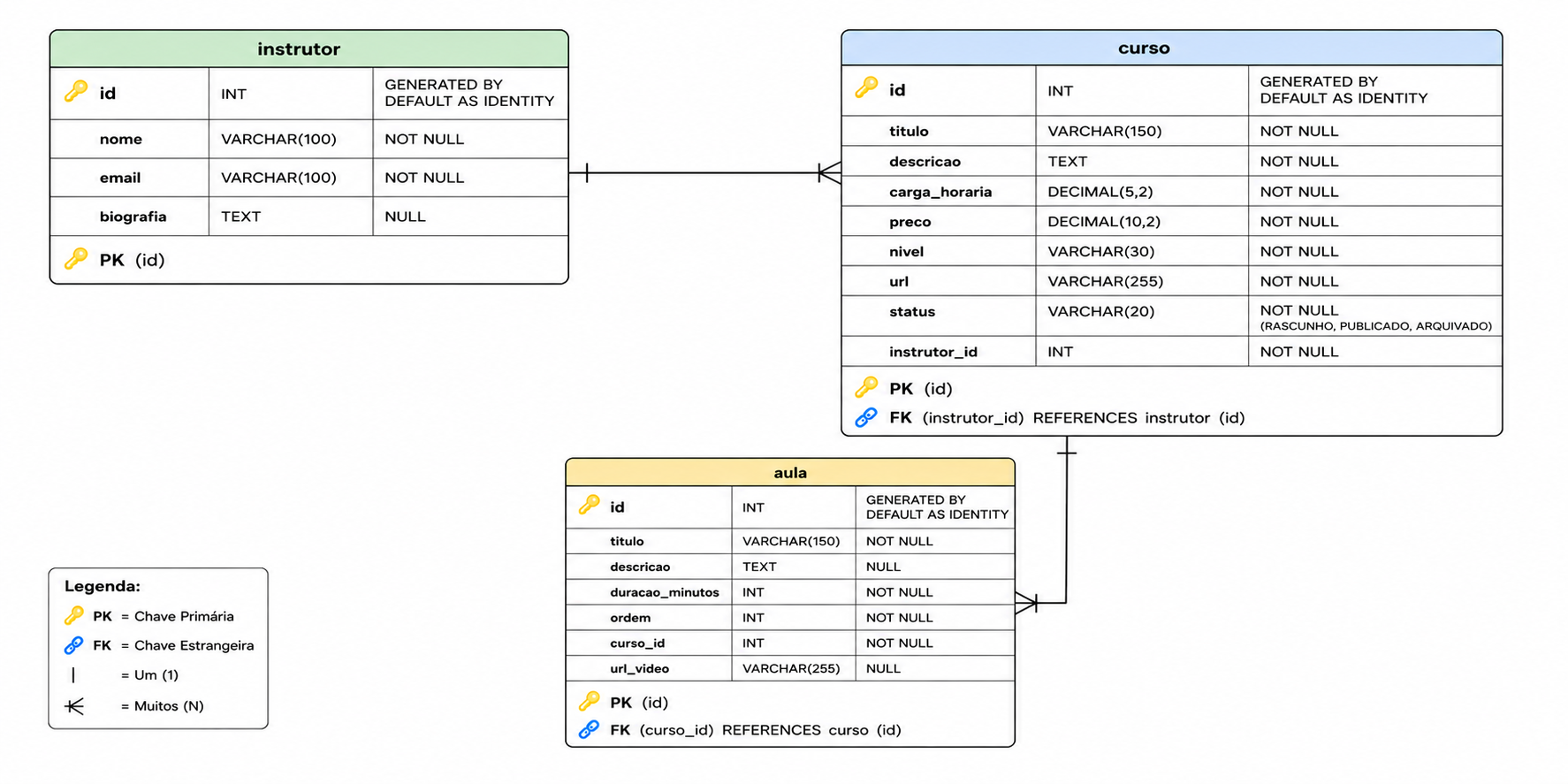
- Relacionamento entre as entidades:
- relacionamento 1:N entre
instrutorecurso: Um instrutor pode ministrar vários cursos, enquanto um curso é ministrado por apenas um instrutor; - relacionamento 1:N entre
cursoeaula: Um curso pode ter várias aulas, enquanto uma aula pertence a apenas um curso.
- relacionamento 1:N entre
#Criando o Banco
-
Abra sua instância do
pgAdmine crie um banco chamadocursos_pweb1. -
Você poderia criar as tabelas manualmente, mas vamos deixar que o Hibernate faça isso para nós. Na próxima parte, quando criarmos as entidades JPA em nossa aplicação, o Hibernate irá gerar automaticamente as tabelas no banco de dados.
#Estrutura Inicial do Projeto
-
No VS Code, crie um novo projeto Maven vazio (sem
archetype). -
Em
groupIdutilizecom.seunomee emartifactIdutilizecursos_pweb1.
Estrutura esperada:
cursos_pweb1
├── pom.xml
|
└── src
├── main
| ├── java/com/seunome
| | ├── Main.java
| └── resources
└── test- Crie os pacotes
entitiesedbdentro do seu pacote base:
src/main/java/com/seunome
├── Main.java
├── entities
└── dbOnde:
- entities: Entidades JPA (
Instrutor,CursoeAula). - db: Classes de configuração da camada de persistência, que terão a responsabilidade, por exemplo, de criar e gerenciar a
EntityManagerFactory.
- No arquivo
pom.xmladicione as dependências do Hibernate e da JPA, além do driver JDBC do PostgreSQL.
<dependencies>
<dependency>
<groupId>org.hibernate.orm</groupId>
<artifactId>hibernate-core</artifactId>
<version>7.4.2.Final</version>
</dependency>
<dependency>
<groupId>jakarta.persistence</groupId>
<artifactId>jakarta.persistence-api</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.7.11</version>
</dependency>
</dependencies>- Ainda no arquivo
pom.xml, verifique a versão do Java utilizada no projeto. Nesta série de artigos, vou utilizar o Java 21:
<properties>
<maven.compiler.source>21</maven.compiler.source>
<maven.compiler.target>21</maven.compiler.target>
</properties>#Primeiro Commit
Para finalizar esta primeira parte, vamos inicializar o repositório Git e fazer o primeiro commit com a estrutura inicial do projeto. Em nossas práticas, iremos sempre versionar o código fonte utilizando o Git, com mensagens de commit descritivas seguindo o padrão Conventional Commits.
-
Abra um terminal na pasta raíz do projeto e inicialize o repositório Git.
git init -
Crie um arquivo
.gitignorena raiz do projeto e adicione as seguintes linhas:target/ *.classExplicando:
- O arquivo
.gitignoreé utilizado para informar ao Git quais arquivos e pastas devem ser ignorados, ou seja, não versionados. target/é a pasta onde o Maven gera os arquivos compilados e empacotados do projeto, que não precisam ser versionados.*.classé utilizado para ignorar todos os arquivos.classgerados pelo compilador Java, que também não precisam ser versionados.
- O arquivo
-
No terminal, adicione todos os arquivos do projeto ao repositório Git e faça o primeiro commit:
git add . git commit -m ":tada: init: cria a estrutura inicial do projeto"Acesse https://github.com/iuricode/padroes-de-commits para entender o padrão de mensagens de commit que utilizaremos.
-
Se você nunca configurou o Git em sua máquina, provavelmente o comando acima irá gerar um erro. Nesse caso, configure seu nome e email com os comandos abaixo:
git config --global user.name "Seu Nome" git config --global user.email "seu.email@exemplo.com"- Seu email deve ser o mesmo que você utiliza para acessar o GitHub.
-
Crie um repositório no GitHub com o mesmo nome do projeto (
cursos_pweb1) e faça o push do seu repositório local para o remoto.git branch -M main git remote add origin <URL_DO_REPOSITORIO> git push -u origin mainExplicando:
git branch -M main: renomeia a branch principal paramain(padrão atual do GitHub);git remote add origin <URL_DO_REPOSITORIO>: adiciona o repositório remoto do GitHub comoorigin;git push -u origin main: envia o repositório local para o remoto, criando a branchmainno GitHub.
-
Acesse o repositório no GitHub e verifique se o código foi enviado corretamente.
#⏩ Próximos Passos
Na próxima parte construiremos o projeto completo, incluindo:
- Configuração detalhada do
persistence.xml; - Criação das entidades
Instrutor,CursoeAulacom seus respectivos atributos e relacionamentos; - Explicação aprofundada das anotações de mapeamento
@Entity,@Table,@Id,@GeneratedValue,@ManyToOne,@JoinColumn; - Implementação completa das classes de domínio;
- Primeira execução do Hibernate gerando SQL automaticamente.